In the previous post about Containers and Cloud Security, I noted that most of the tenants of a Cloud Service Provider (CSP) could safely not worry about the Horizontal Attack Profile (HAP) and leave the CSP to manage the risk. However, there is a small category of jobs (mostly in the financial and allied industries) where the damage done by a Horizontal Breach of the container cannot be adequately compensated by contractual remedies. For these cases, a team at IBM research has been looking at ways of reducing the HAP with a view to making containers more secure than hypervisors. For the impatient, the full open source release of the Nabla Containers technology is here and here, but for the more patient, let me explain what we did and why. We’ll have a follow on post about the measurement methodology for the HAP and how we proved better containment than even hypervisor solutions.
The essence of the quest is a sandbox that emulates the interface between the runtime and the kernel (usually dubbed the syscall interface) with as little code as possible and a very narrow interface into the kernel itself.
The Basics: Looking for Better Containment
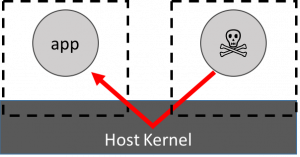 The HAP attack worry with standard containers is shown on the left: that a malicious application can breach the containment wall and attack an innocent application. This attack is thought to be facilitated by the breadth of the syscall interface in standard containers so the guiding star in developing Nabla Containers was a methodology for measuring the reduction in the HAP (and hence the improvement in containment), but the initial impetus came from the observation that unikernel systems are nicely modular in the libOS approach, can be used to emulate systemcalls and, thanks to rumprun, have a wide set of support for modern web friendly languages (like python, node.js and go) with a fairly thin glue layer. Additionally they have a fairly narrow set of hypercalls that are actually used in practice (meaning they can be made more secure than conventional hypervisors). Code coverage measurements of standard unikernel based kvm images confirmed that they did indeed use a far narrower interface.
The HAP attack worry with standard containers is shown on the left: that a malicious application can breach the containment wall and attack an innocent application. This attack is thought to be facilitated by the breadth of the syscall interface in standard containers so the guiding star in developing Nabla Containers was a methodology for measuring the reduction in the HAP (and hence the improvement in containment), but the initial impetus came from the observation that unikernel systems are nicely modular in the libOS approach, can be used to emulate systemcalls and, thanks to rumprun, have a wide set of support for modern web friendly languages (like python, node.js and go) with a fairly thin glue layer. Additionally they have a fairly narrow set of hypercalls that are actually used in practice (meaning they can be made more secure than conventional hypervisors). Code coverage measurements of standard unikernel based kvm images confirmed that they did indeed use a far narrower interface.
Replacing the Hypervisor Interface
One of the main elements of the hypervisor interface is the transition from a less privileged guest kernel to a more privileged host one via hypercalls and vmexits. These CPU mediated events are actually quite expensive, certainly a lot more expensive than a simple system call, which merely involves changing address space and privilege level. It turns out that the unikernel based kvm interface is really only nine hypercalls, all of which are capable of being rewritten as syscalls, so the approach to running this new sandbox as a container is to do this rewrite and seccomp restrict the interface to being only what the rewritten unikernel runtime actually needs (meaning that the seccomp profile is now CSP enforced). This vision, by the way, of a broad runtime above being mediated to a narrow interface is where the name Nabla comes from: The symbol for Nabla is an inverted triangle (∇) which is broad at the top and narrows to a point at the base.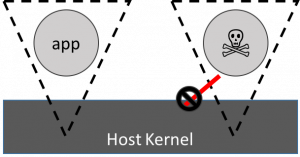
Using this formulation means that the nabla runtime (or nabla tender) can be run as a single process within a standard container and the narrowness of the interface to the host kernel prevents most of the attacks that a malicious application would be able to perform.
DevOps and the ParaVirt conundrum
Back at the dawn of virtualization, there were arguments between Xen and VMware over whether a hypervisor should be fully virtual (capable of running any system supported by the virtual hardware description) or paravirtual (the system had to be modified to run on the virtualization system and thus would be incapable of running on physical hardware). Today, thanks in a large part to CPU support for virtualization primtives, fully paravirtual systems have long since gone the way of the dodo and everyone nowadays expects any OS running on a hypervisor to be capable of running on physical hardware1. The death of paravirt also left the industry with an aversion to ever reviving it, which explains why most sandbox containment systems (gVisor, Kata) try to require no modifications to the image.
With DevOps, the requirement is that images be immutable and that to change an image you must take it through the full develop build, test, deploy cycle. This development centric view means that, provided there’s no impact to the images you use as the basis for your development, you can easily craft your final image to suit the deployment environment, which means a step like linking with the nabla tender is very easy. Essentially, this comes down to whether you take the Dev (we can rebuild to suit the environment) or the Ops (the deployment environment needs to accept arbitrary images) view. However, most solutions take the Ops view because of the anti-paravirt bias. For the Nabla tender, we take the Dev view, which is born out by the performance figures.
Conclusion
Like most sandbox models, the Nabla containers approach is an alternative to namespacing for containment, but it still requires cgroups for resource management. The figures show that the containment HAP is actually better than that achieved with a hypervisor and the performance, while being marginally less than a namespaced container, is greater than that obtained by running a container inside a hypervisor. Thus we conclude that for tenants who have a real need for HAP reduction, this is a viable technology.
- Technically paravirtual elements survive in the form of paravirtual drivers, which are drivers corresponding to no physical hardware but which allow a guest and host to collaborate over I/O. Paravirt drivers don’t spoil the ability to run on physical systems because the OS kernel simply selects the best available driver for the job on the platform, thus allowing it to work on virtual and physical platforms alike, so the main aversion was for paravirtual elements in core code